So I took this EXCELLENT 5-star course on Pluralsight about adding DDD concepts into a legacy project and just wanted to summarize some of the concepts and takeaways. Learned a lot.
Domain-Driven Design: Working with Legacy Projects by Vladimir Khorikov
Legacy projects don’t always have to mean “sloppy projects” or a “big ball of mud”. In many cases, due to factors like “time constraints and deadlines, high turnover, no time to refactor, etc..”, a system eventually evolves into a big ball of mud. In other cases, you can have cleanly written legacy projects.
How and whether or not DDD should be introduced into legacy projects is a case-by-case.
Supposing you have a big-enough feature to introduce into a big ball of mud and the fear of making significant changes (that touch a lot of area) in the legacy project will open up the door for “A significant risk of breaking existing functionality without the resources to go back and carefully regression test everyting”, it’s then worth stepping back an examining the alternative to this.
You don’t have to use DDD as you can still create an anti-corruption layer but DDD is a natural.
The key advantage to doing this instead of just placing all of the new features into the existing application/code base are:
– Minimize regression testing and the risk that your new feature(s)/change(s) may have broken something in the legacy application. Imagine having to wonder if your new feature(s) broke something down the line in the existing codebase that used to always work. With this approach, you’re going out of your way to “leave everything else out there alone” and just add your feature(s) in such a way that the existing application(s) code does not really know about it.
One key point to note here:
It’s very possible/likely that the actual area that these features will be included (ie, hooks into the new feature(s)) are will be in a few areas of the legacy application but they will be isolated. For example, if this new feature involves a new screen, the interface to your new feature(s) in your bounded context will involve “pulling in the DLL/share library (or even API)” into your legacy codebase. But it will be isolated.
Some key “tools” for this:
– Create an “island”(module/namespace which is in a different project) or “bounded context” which contains your bounded context for ALL of the features you need to introduce.
* Protect this “context” with an anti-corruption layer that will sit between the legacy app and this context.
There are different ways to do this:
1. The legacy app and bounded context share the same DB *but* the bounded context (per se) at its “core domain” will not know about the DB structure.

ACL = Anti Corruption Layer:
The idea is that this ACL will contain the protection between the new bounded context of features and the legacy application. It will prevent the “messiness” (if the legacy system is messy) from bleeding into (and influencing) your new context.
In the above example, the ACL would contain such features like:
– A “logical repository” for your new bounded context to use that will (behind the scenes) map the “ubiquitous language” for your new domain into the legacy app. That will also include logic to update the database tables, etc.. Your new context won’t know about the schema of the old system. Only the entities/value objects that you use in the bounded context. The ACL will container “maps” that will translate your entities/value objects into what your legacy application understands.
So you will have a clean isolated seperation of concerns.
2. The bounded context is autonomous by having a seperate data storage
This approach is similar to the above approach except that the bounded context (new system) is completely isolated and packaged up from the legacy system with no direct dependency. ONLY the ACL would contain the repository mappings (and dual DB operations to go back and forth between the 2 DB’s) and act as the mediator/broker between the legacy application and bounded context.
This approach is more natural with that of a microservice (it’s own DB and you could employ events (potentially) to communicate back and forth).

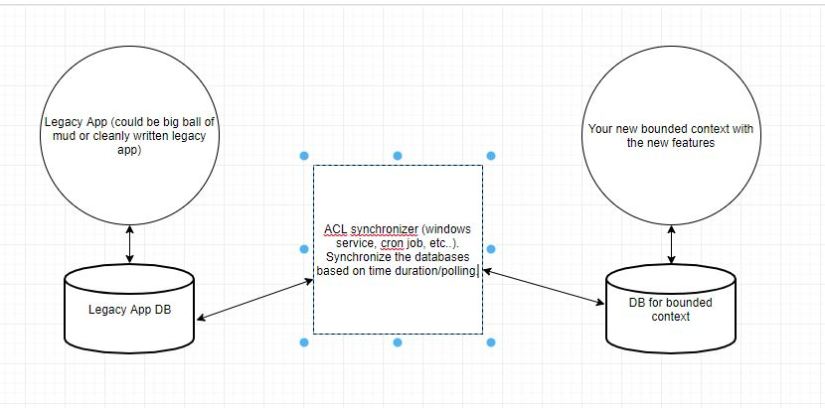
3. Have a syncronizer ACL rather than an internal ACL
In this example, the ACL is a job (or multiple jobs) would run that would poll the state of the desired table(s) in the 2 db(s). The end result the 2 DB’s would be in sync with “eventual consistency”(not ACID but Base).